





基于推理大模型与知识图谱构建信用债券数智化分析新范式
- 创业
- 2025-04-07 19:02:03
- 13
◇ 作者:中国邮政储蓄银行金融市场部 杨再宝 张涵 刘晨晔 程昊
◇ 本文原载《债券》2025年3月刊
摘 要
受知识图谱、大语言模型等前沿人工智能(AI)技术的影响,信用债券的信用分析范式正在发生巨大变革。相较于高成本且闭源的GPT4.0模型,以深度求索(DeepSeek)为代表的前沿低成本、高效能推理大模型,为大规模应用AI开展信用分析提供了可能。本文梳理了信用债券分析数智化的发展趋势,并通过实践研究,论证了推理大模型和知识图谱技术在信用债券分析领域的应用潜力。
关键词
推理大模型 信用债券分析 知识图谱
信用债券分析数智化发展概况
信用债券分析的数智化发展主要历经了三阶段:一是以财务比率分析为代表的传统评估框架(Altman, 1968),二是由结构化模型与连接(Copula)方法奠定的现代信用组合分析体系(Merton, 1974; Treacy et al., 2000),三是当前基于机器学习的智能评估体系。近年来,以机器学习为代表的人工智能(AI)技术取得突破性进展,并在识别信用风险非线性特征方面表现卓越。基于这种优势,众多国内金融机构积极采取行动,已系统性地部署机器学习模型群组,挖掘个人及中小企业客户的海量信用数据,构建多维度特征工程,实现了信用画像颗粒度与预测精度的显著提升(徐劲等,2022)。
当前,金融机构在将机器学习技术应用于信用债券分析时面临一定的困难:其一,标的资产集中于大型企业集团,单笔大金额形成的风险高集中度与机器学习依赖的大数定律存在根本冲突;其二,集团化经营衍生的复杂股权嵌套和差异化的业务范围显著增加了企业异质性,导致模型在特征工程阶段面临跨主体可比维度缺失问题;其三,市场主体数量较少导致训练样本规模不足,可能引发共线性或过拟合问题。尽管如此,AI技术在信用债券分析领域仍然有巨大的应用潜力,但需要构建更具有针对性的应用范式。
当前,以大语言模型(Large Language Model,LLM)为代表的生成式人工智能领域取得了一系列突破,发展出具备推理能力的大语言模型(Reasoning LLM,以下简称“推理大模型”)技术和基于知识图谱的检索增强生成技术(graph based retrieval-augmented generation, GraphRAG),为信用债券分析提供了一种切实可行的数智化范式。
信用债券分析数智化发展趋势
(一)研究方法:从定量主导向混合方法转型
在信用债券分析中,传统的信用评级模型过度依赖财务指标等结构化数据 (Blume et al., 1998),其可能因方法论存在问题而导致结果错误,即存在“定量陷阱”(王正绪等,2023)。与此同时,定性因素发挥着愈加重要的作用,如社会评价、政府关系、融资支持力度等,已成为衡量信用还款能力的重要因素。鉴于此,信用分析师通常会在定量模型的基础上,依据定性因素进行调整(Bozanic et al., 2023),将行业政策、政府支持力度等难以量化的定性因素考虑在内。过去,评估这些定性因素极度依赖分析师的个人知识储备和从业经验,而大语言模型的蓬勃发展带来了新的可能,投资机构可以通过模型微调或简单的上下文学习(In-Context Learning),将这些知识和经验融入信用分析模型,从而实现定性分析的自动化和标准化。
(二)评估体系:从结果输出到过程透明
基于传统机器学习的评估体系在研究方法上侧重于分类或回归,即通过大数据构建监督学习模型,直接依据数据结果对企业信用状况予以分级、给出违约概率。然而,这样的方法缺乏可解释性,且存在弊端:一方面,风险归因缺失,导致无法判别特定风险因子对评级结果的边际贡献;另一方面,决策支持断层,导致难以将模型的输出转换为可操作的避险策略。相比而言,推理大模型具备显著的优势。一方面,推理大模型能够以自然语言输出分析结果,具备可读性和可解释性;另一方面,深度推理大模型能够给出推理过程,分析步骤清晰透明,有助于投资者依据推理过程进行风险归因,为投资决策提供有力支持。
(三)数据架构:从结构化向多维度整合
信用债券分析面临多源异构数据的整合困境,传统模型依赖结构化数据建模的局限性日益凸显。除了财务数据,发债企业的信用风险评估还需要整合文本、时空、关系等多维度数据特征。其中,文本维度包括募集说明书、招股书等非结构化文档及舆情信息,时空维度包括供应链地理数据与区域经济热力图等信息,关系维度涉及股权穿透网络、业务往来与债务担保关联图谱等内容。当前,图数据库和知识图谱技术日臻成熟,其天然适配此类数据的构建和分析。GraphRAG技术为知识图谱与推理大模型搭建了桥梁,使得投资机构既能通过知识图谱缓解推理大模型的幻觉问题(hallucination,即模型输出不准确或完全错误的信息),又能够借助推理大模型大幅降低知识图谱的使用成本和难度。
(四)技术应用:从人机分治到人机协同
在进行传统信用债券分析时,基于复杂模型的信用评级过程与分析师的分析过程往往并行推进。由模型得到的结果通常起防范风险的作用,分析师的结论起体现风险偏好的作用,在最终投资决策时,二者相互融合、相互制约。这种人机分治的模式使得分析师难以理解模型结论,也使得模型无法快速响应市场变化。此外,分析师技能的提升取决于其对固定收益市场的理解程度及对发债企业认识的深度,模型精度的提升依赖于数据的拓展和模型的优化,但两者之间亦难以相互学习。在大语言模型的助力下,投资机构可以构建具备自主性、适应性和交互能力的信用债券分析AI智能体。AI智能体能够迅速学习人类经验并校正分析结果,还能够向分析师输出自身的分析经验,从而实现人机协同开展信用债券分析。
基于推理大模型和知识图谱
构建信用债券分析AI智能体的实践方案
AI智能体是大模型发挥业务价值的重要载体,除了存储信息的知识库,通常还包括4个模块:一是感知模块,负责读取和收集相关数据;二是决策模块,作为智能体的中枢,自主规划各类任务,依据数据进行决策判断,确定下一步执行方案;三是执行模块,落实决策模块提出的操作要求,例如运用搜索工具进行计算等;四是学习模块,依据外界变化或与外界的交互来调整规划方案,优化相关决策。
信用债券分析AI智能体契合信用债券分析的数智化发展趋势,能够通过多种技术组合提升生产效能。本文基于推理大模型和知识图谱技术展开实践,围绕发债企业构建了信用债券分析AI智能体。
(一)感知模块——构建知识图谱
2024年7月,微软公司推出基于大语言模型的知识图谱生成与检索框架。该框架由大语言模型阅读文字资料,抽取每段文字中所涉及的三元素(实体、属性和关系),并对三元素加以描述,从而生成知识图谱。其中,文字抽取环节对模型的逻辑性有极高要求,中小模型难以承担,必须依靠千亿参数以上的超大模型。该环节主要致力于处理大量同质化任务,要求结果具有一致性和准确性,不过任务相对简易,暂不需要推理大模型参与。
在实践中,笔者运用深度求索V3(DeepSeek-V3)模型来阅读发债企业的募集说明书、评级报告、关联企业工商信息、风险舆情等材料信息,生成发债企业的知识图谱,并将地区经济、财务数据等结构化数据注入知识图谱,可构建出一张能够让AI理解的全市场发债企业知识图谱(见图1)。同时,依据社区检索算法(如Leiden算法)对发债企业和所有关联企业、个人进行多维度聚类,挖掘传染性风险。在知识图谱抽取过程中,一旦发现异常情况,感知模块便会及时向决策模块进行报告。
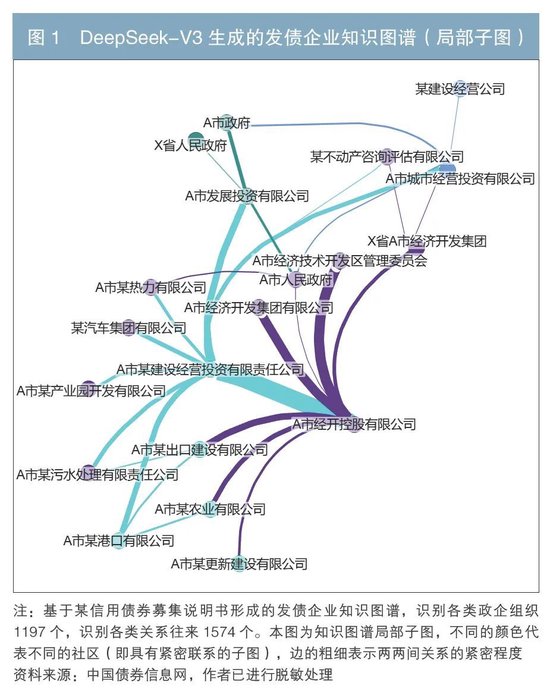
笔者在图谱构建过程中,开创性地融合了非结构化数据与结构化数据,并引入算法去重机制,进一步提升了图谱的知识密度,减少了多个图谱的维护成本。在图谱生成时,以协变量作为节点关系的辅助性事件记录,可在不提升图谱复杂度的情况下大幅提升图谱的信息承载能力。当前,得益于混合专家(Mixture of Experts, MOE)架构大模型的低推理成本和图谱结构优化,知识图谱的构建成本大幅降低。据测算,将2024年全部银行间市场发行的信用债券1募集说明书构建成一张知识图谱,总费用只需要大约60万元。如进行本地化部署后,所需开销会更低。
(二)决策模块——规划和反思
决策模块的主要作用在于对感知模块发现的风险进行研判,利用信用分析框架定期更新企业信用评级和信用报告,同时回答分析师的提问。上述功能皆为低频、复杂且极具个性化的任务,AI需要将任务拆解为条理清晰的步骤依次执行,每个执行过程会涉及工具(如知识图谱检索工具、网络搜索工具、计算工具)调用,在执行遭遇问题时要能够自主解决问题(如反思执行方案、询问人类、跳过步骤)。
在推理大模型出现之前,业界通常采用思维树(ToT)框架、语言代理树搜索(LATS)框架来进行任务拆解、执行、评估,以增强普通大语言模型的规划、反思能力。然而,由于搜索空间有限,此类方案只能在推理成本、响应时效和决策效果三者之中择其一。推理大模型的出现使得上述三者几乎能够同时兼顾。在实践中,笔者以DeepSeek-R1模型作为智能体的决策模块,对任务步骤进行规划、拆解,生成的系统性信用分析框架如图2所示。

(三)执行模块——检索知识图谱
在执行阶段,最为重要的任务是响应决策阶段所提出的信息检索需求,比如获取发债企业财务指标、掌握企业与政府之间的业务往来情况。此前在感知阶段,已经构建了全市场一体化的发债企业知识图谱,因此只需要大语言模型依据知识图谱按图索骥进行检索,便能准确获取企业的特定信息。执行阶段与感知阶段相似,均为同质化的单一任务。
得益于知识图谱的高密度信息承载能力,在检索知识图谱时对算力的需求大大降低。此外,笔者在检索过程中引入分级检索机制,进一步实现了节约算力、提升准确率的效果。
(四)学习模块——学习总结经验
学习模块包含两部分功能:其一,对分析师已有的分析成果予以总结提炼,以供决策模块参考;其二,对进行信用分析时发现的异常情况,提炼出全新的分析视角和维度,经分析师验证后供决策模块参考。与决策模块类似,学习模块需要具备复杂的推理能力,适合以深度推理大模型作为基础底座。在实践中,笔者采用DeepSeek-R1模型阅读了8个重要行业的313篇研究报告,形成的行业分析要点可供决策模块参考。
未来展望
相比传统信用债券分析方法,以推理大模型和知识图谱为基础的信用债券分析AI智能体在效率、成本、稳定性等方面呈现显著优势。其应用普及,一方面能够有效降低投资机构信用评估成本,增强信用债券定价能力,提升交易决策水平;另一方面有助于金融机构更加高效快捷地发掘优质客户,拓展服务实体经济的深度和广度。
以DeepSeek系列模型为代表的高性能、低成本开源大语言模型的影响正不断显现,未来,相关创新也将优化金融市场的数智化生态。特别是具备强大逻辑分析能力的推理大模型,有望在信用分析、投资决策等金融生产活动中发挥重要作用。随着大语言模型、多模态算法、知识图谱等技术的持续迭代,AI在金融领域的作用将进一步凸显,并强化金融行业的价值发现功能,使逆向选择成本大幅降低,从而最终降低全社会的融资成本,进一步促进金融资源的有效配置。
注:
1.信用债券依据万得(Wind)口径,其统计数据显示,2024年银行间市场共发行信用债券12027只。
参考文献
[1]王正绪,栗潇远. 实证社会科学研究中的因果推断:挑战与精进[J]. 社会科学,2023(8).
[2]徐劲,许皓玮,葛善伟. 运用机器学习强化银行风险预警[J]. 中国金融,2022(2).
[3]Altman E I. Financial Ratios, Discriminant Analysis and The Prediction of Corporate Bankruptcy[J]. Journal of Finance, 1968, 23(4).
[4] Blume M E, Lim F, MacKinlay A C. The declining credit quality of US corporate debt: Myth or reality?[J]. The journal of finance, 1998, 53(4).
[5]Bozanic Z, Kraft P, Tillet A. Qualitative disclosure and credit analysts’ soft rating adjustments[J]. European Accounting Review, 2023, 32(4).
[6]Ji S, Pan S, Cambria E, et al. A Survey on Knowledge Graphs: Representation, Acquisition, and Applications[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 33(2).
[7] Merton R C. On The Pricing of Corporate Debt: The Risk Structure of Interest Rates[J]. Journal of Finance, 1974, 29(2).
[8] Treacy W F, Carey M. Credit Risk Rating Systems at Large US Banks[J]. Journal of Banking & Finance, 2000, 24(1-2).
相关文章
热门文章

最准一肖一码100%准,埋伏精选答案落实_手机端862.43
2024-12-27香港出码综合走势图,代劳精选解释落实_The56.43.44
2024-12-27白小姐三肖三码必开一码开奖,窃视精选解释落实_ios93.58.89
2024-12-27香港内部马料免费资料亮点,小节精选解释落实_iPhone91.81.51
2024-12-27香港最准最快的资料免费 ,淘气精选答案落实_制作版8.8
2024-12-27
美国对以色列宣布杀害辛瓦尔表示欢迎,呼吁加沙“第二天”
2024-12-2077778888管家婆必开一肖,不能自已精选解释落实_网页版96.46.20
2024-12-27
特朗普呼吁对杀害美国公民和警察的移民判处死刑
2024-12-23
有话要说...